
Исследование Microsoft, опубликованное 17 апреля 2026 года и дополненное уточнениями в официальном блоге 15 мая, стало одним из наиболее показательных тестов реальной надёжности современных языковых моделей в условиях, приближенных к офисной автономной работе. Его главный вывод звучит достаточно сдержанно, но по сути довольно жёстко: текущие ИИ-системы пока не готовы полностью заменить человека там, где требуется длительное последовательное выполнение задач с документами без постоянного контроля.
Суть эксперимента заключалась не в привычных тестах «вопрос-ответ» и не в разовых заданиях, а в моделировании реальной рабочей среды, где документ постепенно редактируется, уточняется, переписывается и дополняется в течение множества шагов. Именно такой формат ближе всего к тому, как сегодня пытаются использовать ИИ в офисных процессах — от подготовки отчётов до юридических и аналитических документов.
Исследователи протестировали 19 современных моделей, включая Gemini 3.1 Pro, Claude 4.6 Opus и GPT 5.4. Задачи охватывали 52 профессиональные области: программирование, бухгалтерский учёт, анализ данных, научные тексты, кристаллографию, нотную запись и другие специализированные форматы, где важна не только генерация текста, но и сохранение структуры, смысла и точности на протяжении длинной цепочки изменений.
Ключевое отличие эксперимента от стандартных бенчмарков — отсутствие промежуточного человеческого контроля. Модель должна была самостоятельно вести документ через серию последовательных изменений, имитируя сценарий, в котором сотрудник полностью делегировал задачу системе и вернулся к результату только в конце.
И именно здесь проявилась основная проблема.
Даже наиболее продвинутые модели начинали постепенно искажать содержание. В среднем около 25% информации терялось или изменялось уже после 20 последовательных шагов редактирования в лучших системах. Если учитывать всю выборку моделей, средний уровень искажений достиг примерно 50%. Это означает, что каждый второй элемент информации в длинной цепочке работы мог быть изменён, упрощён или интерпретирован иначе, чем в исходном тексте.
Важно, что речь не идёт о грубых очевидных ошибках. Напротив, исследователи подчёркивают, что изменения часто выглядят логично на каждом отдельном шаге. Проблема возникает из-за накопительного эффекта: небольшие отклонения на ранних этапах постепенно складываются в значительное смещение смысла. Документ «плывёт» не резко, а почти незаметно, теряя точность по мере увеличения длины цепочки.
Этот эффект особенно выражен в сложных задачах с большим объёмом контекста. Чем длиннее документ и чем больше последовательных операций выполняет модель, тем выше вероятность того, что итоговый результат будет существенно отличаться от исходного замысла.
При этом исследование зафиксировало важное исключение. В задачах программирования на Python большинство моделей сохраняли точность выше 98% даже после 20 итераций изменений. Авторы объясняют это особенностями формального языка: код имеет строгую структуру, синтаксические ограничения и однозначную проверяемость, что резко снижает пространство для накопления ошибок. Проще говоря, там, где есть чёткие правила, ИИ «дрейфует» значительно меньше.
Авторы исследования — Филипп Лабан, Тобиас Шнабель и Дженнифер Невилль — делают осторожный, но принципиальный вывод: современные языковые модели не обладают достаточной надёжностью для длительной автономной работы без контроля человека. Они подчёркивают, что в реальных сценариях часть этих проблем может компенсироваться промежуточной проверкой, но именно её отсутствие и было предметом эксперимента, поскольку именно так сегодня всё чаще представляют «полную автоматизацию» офисных процессов.
Дополнительный акцент делается на природе самой ошибки. Речь идёт не о случайных сбоях, а о системном эффекте накопления отклонений. Это принципиально важное наблюдение: модель может быть точной в краткосрочном действии, но терять стабильность при длительном «самоподдерживающемся» процессе.
Методология исследования опубликована в открытом доступе, что позволяет независимым командам воспроизводить результаты и проверять границы обнаруженного эффекта.
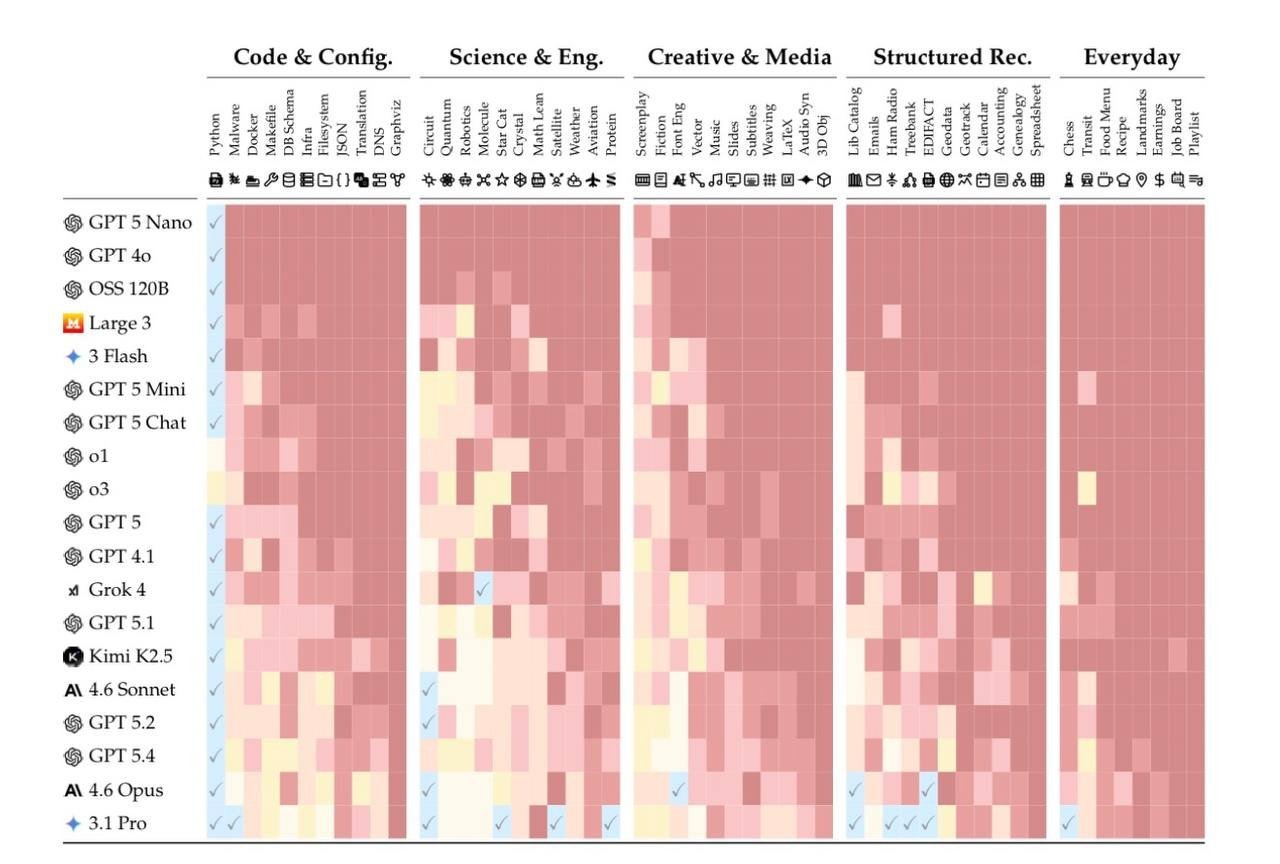
Сравнение ИИ в реальных рабочих задачах
Интересный исторический контекст помогает лучше понять масштаб проблемы. В 1970-х первые промышленные роботы также демонстрировали схожее поведение: при длительной работе без перекалибровки накапливались механические погрешности, которые приводили к отклонениям в сборочных линиях. Тогда проблема была решена не отказом от автоматизации, а введением регулярных контрольных точек и систем коррекции. По сути, современная ситуация с языковыми моделями воспроизводит тот же класс ограничений, только уже на уровне информации, а не механики.
Именно поэтому индустрия всё чаще приходит к гибридной модели: ИИ выполняет основную работу, но человек остаётся точкой проверки и финального контроля.
Практические последствия уже начинают проявляться. В индустрии зафиксированы случаи, когда ошибки в длинных цепочках автоматизированных действий приводили к реальным финансовым потерям, включая инцидент с ошибочным переводом около 441 000 долларов из-за одной неточности в ИИ-агенте. Такие ситуации показывают, что накопительный эффект ошибок не ограничивается текстом — он напрямую переходит в экономическую плоскость.
В итоге исследование Microsoft фактически фиксирует текущую границу развития: ИИ уже способен выполнять сложные задачи, но пока не способен гарантированно сохранять точность при длительной автономной работе без внешнего контроля.
ОТКАЗ ОТ ОТВЕТСТВЕННОСТИ: Все материалы, представленные на этом сайте (https://wildinwest.com/), включая вложения, ссылки или материалы, на которые ссылается компания, предназначены исключительно для информационных и развлекательных целей и не должны рассматриваться как финансовая консультация. Материалы третьих лиц остаются собственностью их соответствующих владельцев.